线性分类¶
| 日期 | 2011-05-29 (最后修改), 2011-05-29 (创建) |
|---|
Fisher 线性判别¶
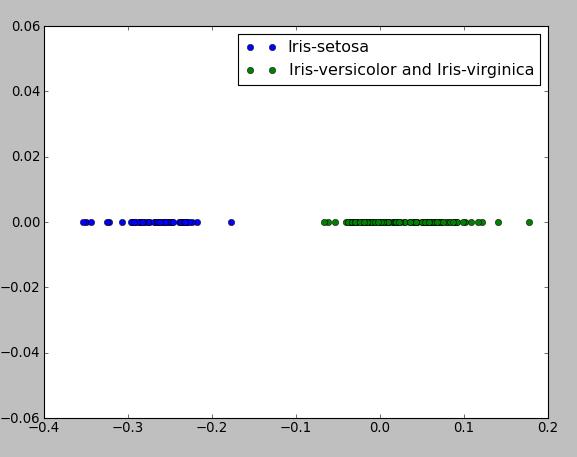
第一个示例展示了 Fisher 线性分类器在二分类问题中的实现,该算法在 Christopher M Bishop 的“模式识别与机器学习”一书中进行了详细描述(第 186 页,第 4.1 节)。该算法的主要思想是,我们尝试降低输入向量 X 的维数,并使用方程 y=W.T X 将其投影到一维空间,其中 W.T 是权重行向量,我们调整权重向量 W 并选择最大化类分离的投影。以下程序使用著名的 Iris 数据集,包含 150 个实例和 4 个属性(4 维空间),目标向量包含标签:“Iris-setosa”、“Iris-virginica”、“Iris-versicolor”,因此我们有 3 个类,但在此情况下,我们可以假设我们有标签为“Iris-setosa”的类 1 和其他实例的类 2。Iris 数据集可在此处获得:http://archive.ics.uci.edu/ml/datasets/Iris/ 或此处(逗号分隔格式) - bezdekIris.data.txt
在 [ ]
#! python
from __future__ import division
import numpy as np
import matplotlib.pyplot as plt
def read_data():
f=open("Iris.txt", 'r')
lines=[line.strip() for line in f.readlines()]
f.close()
lines=[line.split(",") for line in lines if line]
class1=np.array([line[:4] for line in lines if line[-1]=="Iris-setosa"], dtype=np.float)
class2=np.array([line[:4] for line in lines if line[-1]!="Iris-setosa"], dtype=np.float)
return class1, class2
def main():
class1, class2=read_data()
mean1=np.mean(class1, axis=0)
mean2=np.mean(class2, axis=0)
#calculate variance within class
Sw=np.dot((class1-mean1).T, (class1-mean1))+np.dot((class2-mean2).T, (class2-mean2))
#calculate weights which maximize linear separation
w=np.dot(np.linalg.inv(Sw), (mean2-mean1))
print "vector of max weights", w
#projection of classes on 1D space
plt.plot(np.dot(class1, w), [0]*class1.shape[0], "bo", label="Iris-setosa")
plt.plot(np.dot(class2, w), [0]*class2.shape[0], "go", label="Iris-versicolor and Iris-virginica")
plt.legend()
plt.show()
main()
概率生成模型¶
该程序是针对 K 类问题的概率生成模型的实现,该模型在 Christopher M Bishop 的“模式识别与机器学习”一书(第 196 页,第 4.2 节)中也有描述。我们试图学习每个类别 K 的类条件密度(似然)p(x|Ck) 和先验概率密度 p(Ck),然后我们可以使用贝叶斯规则计算后验概率 p(Ck|x)。这里我们假设 p(x|Ck) 是具有参数 uk - 类 K 的均值向量、Sk 的 4D 高斯分布
- 类 K 的协方差矩阵,以及所有 k 的 p(Ck) 为 1/3。然后我们计算所谓的量 ak(程序中的变量 pc),如果 ak>>aj 对于所有 k!=j 则分配 p(Ck|x)=1 和 p(Cj|x)=0。
在 [ ]
#! python
from __future__ import division
import numpy as np
import matplotlib.pyplot as plt
import math
def read_data():
f=open("Iris.txt", 'r')
lines=[line.strip() for line in f.readlines()]
f.close()
lines=[line.split(",") for line in lines if line]
data=np.array([line[:4] for line in lines if line], dtype=np.float)
class1=np.array([line[:4] for line in lines if line[-1]=="Iris-setosa"], dtype=np.float)
class2=np.array([line[:4] for line in lines if line[-1]=="Iris-virginica"], dtype=np.float)
class3=np.array([line[:4] for line in lines if line[-1]=="Iris-versicolor"], dtype=np.float)
#list of class labels
labels=[]
for line in lines:
strt=line.pop()
labels.append(strt)
#create array of labels
labels=[line.split(",") for line in labels if line]
t=np.zeros(shape=(150, 3))
#create target vector encoded according to 1-of-K scheme
for i in xrange(len(data)):
if labels[i]==["Iris-setosa"]: t[i][0]=1
elif labels[i]==["Iris-versicolor"]: t[i][1]=1
elif labels[i]==["Iris-virginica"]: t[i][2]=1
return class1, class2, class3, data, t
def gaussian(x, mean, cov):
xm=np.reshape((x-mean), (-1, 1))
px=1/(math.pow(2.0*math.pi, 2))*1/math.sqrt(np.linalg.det(cov))*math.exp(-(np.dot(np.dot(xm.T, np.linalg.inv(cov)), xm))/2)
return px
def main():
class1, class2, class3, data, t=read_data()
count=np.zeros(shape=(150,1))
t_assigned=np.zeros(shape=(150, 3))
cov=np.zeros(shape=(3, 4, 4))
mean=np.zeros(shape=(3, 4))
#compute means for each class
mean1=class1.mean(axis=0)
mean2=class2.mean(axis=0)
mean3=class3.mean(axis=0)
#compute covariance matrices, such that the columns are variables and rows are observations of variables
cov1=np.cov(class1, rowvar=0)
cov2=np.cov(class2, rowvar=0)
cov3=np.cov(class3, rowvar=0)
#compute gaussian likelihood functions p(x|Ck) for each class
for i in xrange(len(data)):
px1=(1/3.0)*gaussian(data[i], mean1, cov1)
px2=(1/3.0)*gaussian(data[i], mean2, cov2)
px3=(1/3.0)*gaussian(data[i], mean3, cov3)
m=np.max([px1, px2, px3])
#compute posterior probability p(Ck|x) assuming that p(x|Ck) is gaussian and the entire expression is wrapped by sigmoid function
pc1=((math.exp(px1)*math.exp(-m))*math.exp(m))/((math.exp(px2)*math.exp(-m)+math.exp(px3)*math.exp(-m))*math.exp(m))
pc2=((math.exp(px2)*math.exp(-m))*math.exp(m))/((math.exp(px1)*math.exp(-m)+math.exp(px3)*math.exp(-m))*math.exp(m))
pc3=((math.exp(px3)*math.exp(-m))*math.exp(m))/((math.exp(px1)*math.exp(-m)+math.exp(px2)*math.exp(-m))*math.exp(m))
#assign p(Ck|x)=1 if p(Ck|x)>>p(Cj|x) for all j!=k
if pc1>pc2 and pc1>pc3: t_assigned[i][0]=1
elif pc3>pc1 and pc3>pc2: t_assigned[i][1]=1
elif pc2>pc1 and pc2>pc3: t_assigned[i][2]=1
#count the number of misclassifications
for j in xrange(3):
if t[i][j]-t_assigned[i][j]!=0: count[i]=1
cov=[cov1, cov2, cov3]
mean=[mean1, mean2, mean3]
t1=np.zeros(shape=(len(class1), 1))
t2=np.zeros(shape=(len(class2), 1))
t3=np.zeros(shape=(len(class3), 1))
for i in xrange(len(data)):
for j in xrange(len(class1)):
if t_assigned[i][0]==1: t1[j]=1
elif t_assigned[i][1]==1: t2[j]=2
elif t_assigned[i][2]==1: t3[j]=3
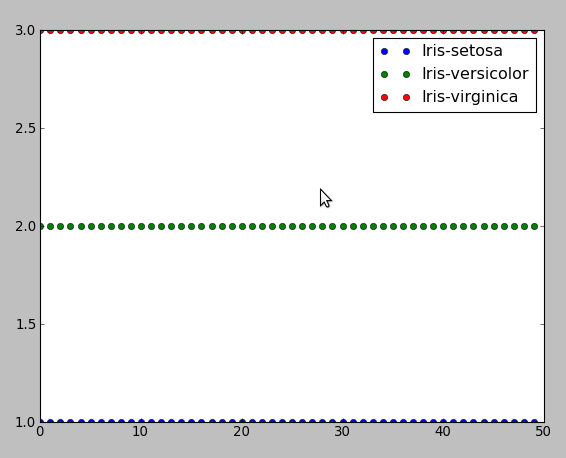
plt.plot(t1, "bo", label="Iris-setosa")
plt.plot(t2, "go", label="Iris-versicolor")
plt.plot(t3, "ro", label="Iris-virginica")
plt.legend()
plt.show()
print "number of misclassifications", sum(count), "assigned labels to data points", t_assigned, "target data", t
main()
该程序导致错误分类的数量为 3,总共 150 个实例。
章节作者:DmitriyRybalkin
附件
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}