相关随机样本¶
| 日期 | 2011-08-16(最后修改)、2010-05-24(创建) |
|---|
注意: 此食谱条目展示了如何使用 SciPy 中的工具从多元正态分布生成随机样本,但实际上 NumPy 包含函数 `numpy.random.multivariate_normal` 来完成相同的任务。
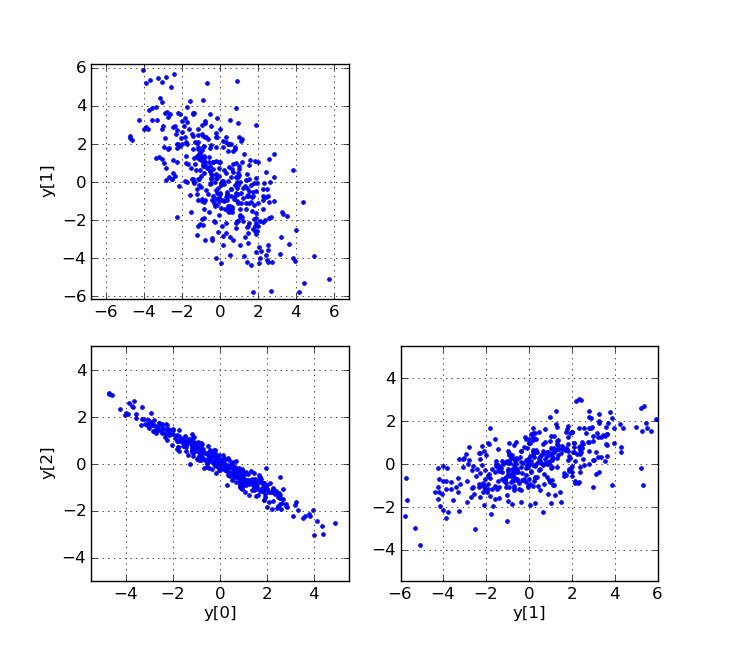
要生成相关的正态分布随机样本,可以先生成不相关的样本,然后将它们乘以矩阵 C,使得 $C C^T = R$,其中 R 是所需的协方差矩阵。例如,可以使用 R 的 Cholesky 分解或从 R 的特征值和特征向量创建 C。
在 [1]
"""Example of generating correlated normally distributed random samples."""
import numpy as np
from scipy.linalg import eigh, cholesky
from scipy.stats import norm
from pylab import plot, show, axis, subplot, xlabel, ylabel, grid
# Choice of cholesky or eigenvector method.
method = 'cholesky'
#method = 'eigenvectors'
num_samples = 400
# The desired covariance matrix.
r = np.array([
[ 3.40, -2.75, -2.00],
[ -2.75, 5.50, 1.50],
[ -2.00, 1.50, 1.25]
])
# Generate samples from three independent normally distributed random
# variables (with mean 0 and std. dev. 1).
x = norm.rvs(size=(3, num_samples))
# We need a matrix `c` for which `c*c^T = r`. We can use, for example,
# the Cholesky decomposition, or the we can construct `c` from the
# eigenvectors and eigenvalues.
if method == 'cholesky':
# Compute the Cholesky decomposition.
c = cholesky(r, lower=True)
else:
# Compute the eigenvalues and eigenvectors.
evals, evecs = eigh(r)
# Construct c, so c*c^T = r.
c = np.dot(evecs, np.diag(np.sqrt(evals)))
# Convert the data to correlated random variables.
y = np.dot(c, x)
#
# Plot various projections of the samples.
#
subplot(2,2,1)
plot(y[0], y[1], 'b.')
ylabel('y[1]')
axis('equal')
grid(True)
subplot(2,2,3)
plot(y[0], y[2], 'b.')
xlabel('y[0]')
ylabel('y[2]')
axis('equal')
grid(True)
subplot(2,2,4)
plot(y[1], y[2], 'b.')
xlabel('y[1]')
axis('equal')
grid(True)
show()

部分作者:WarrenWeckesser、WarrenWeckesser
附件
{kind=link}