MetaArray¶
| 日期 | 2011-08-05(最后修改),2008-03-06(创建) |
|---|
!MetaArray 是一个扩展 ndarray 的类,它添加了对每个轴元数据存储的支持。此类对于存储数据数组以及单位、轴名称、列名称、轴值等非常有用。!MetaArray 对象可以使用命名轴和列任意索引和切片。
在此处下载:MetaArray.py
示例用法¶
以下是一个使用 !MetaArray 存储数据类型的示例
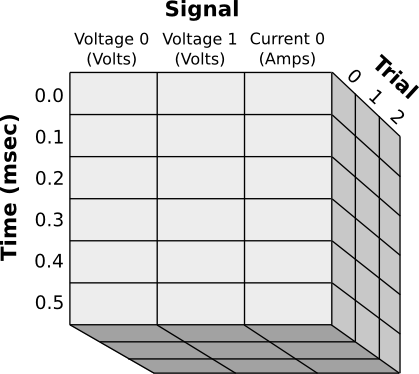
请注意,每个轴都有名称,并且可以存储不同类型的元信息:* Signal 轴具有命名列,每列具有不同的单位 * Time 轴将数值与每行相关联 * Trial 轴使用正常的整数索引
可以以多种方式访问此数组中的数据
data[0, 1, 1]
data[:, "Voltage 1", 0]
data["Trial":1, "Signal":"Voltage 0"]
data["Time":slice(3,7)]
# Constructs MetaArray from a preexisting ndarray and info list
MetaArray(ndarray, info)
# Constructs MetaArray using empty(shape, dtype=type) and info list
MetaArray((shape), dtype=type, info)
# Constructs MetaArray from file written using MetaArray.write()
MetaArray(file='fileName')
info 参数: 此参数指定此 !MetaArray 的所有元数据,必须遵循特定格式。 首先,info 是一个轴描述列表
info=[axis1, axis2, axis3...]
每个轴描述都是一个字典,可能包含:\ * "name":轴的名称\ * "values":一个值列表或 1D ndarray,每个轴索引对应一个值\ * "cols":一个列描述列表 [col1, col2, col3, ...]\ * "units":与 "values" 中列出的数字相关的单位\ 所有这些参数都是可选的。 同样,列描述也是一个字典,可能包含:\ * "name":列的名称\ * "units":此列下所有值的单位\ 在元信息要应用于整个数组的情况下(例如,如果整个数组使用相同的单位),只需在 info 列表的末尾添加一个额外的轴描述。 所有字典都可以包含您想要的任何额外信息。
例如,上面显示的数据集将如下所示
MetaArray((3, 6, 3), dtype=float, info=[
{"name": "Signal", "cols": [
{"name": "Voltage 0", "units": "V"},
{"name": "Voltage 1", "units": "V"},
{"name": "Current 0", "units": "A"}
]
},
{"name": "Time", "units": "msec", "values":[0.0, 0.1, 0.2, 0.3, 0.4, 0.5] },
{"name": "Trial"},
{"note": "Just some extra info"}
]
访问数据¶
可以通过多种方法访问数据:* 标准索引 - 您始终可以像对任何 ndarray 一样对数组进行索引 * 命名轴 - 如果您不记得轴的顺序,您可以指定要索引或切片的轴,如下所示
data["AxisName":index]
data["AxisName":slice(...)]
请注意,由于此语法劫持了原始切片机制,因此如果您想使用命名轴,则必须使用 slice() 指定切片。\ * 列选择 - 如果您不记得要选择的列的索引,您可以用列的名称替换索引号。 列名称列表也是可以接受的。 例如:
data["AxisName":"ColumnName"]
data["ColumnName"] ## Works only if the named column exists for this axis
data[["ColumnName1", "ColumnName2"]]
* 布尔选择 - 按预期工作,例如
sel = data["ColumnName", 0, 0] > 0.2
data[sel]
* 使用 !MetaArray.axisValues() 访问轴值,或简写为 .xvals()。\ * 使用 .axisUnits() 访问轴单位,使用 .columnUnits() 访问列单位\ * 使用 .infoCopy() 直接通过 info 列表访问任何其他参数
文件 I/O¶
data.write('fileName')
newData = MetaArray(file='fileName')
性能提示¶
!MetaArray 是 ndarray 的子类,它覆盖了 `__getitem__` 和 `__setitem__` 方法。 由于这些方法必须在每次访问时更改元信息的结构,因此与本机方法相比,它们的速度非常慢。 因此,许多内置函数在对 !MetaArray 进行操作时运行速度会非常慢。 因此,建议您在执行这些操作之前像这样重新转换数组
data = MetaArray(...)
data.mean() ## Very slow
data.view(ndarray).mean() ## native speed
更多示例¶
一个用于地形图的海拔值二维数组可能如下所示
info=[
{'name': 'lat', 'title': 'Latitude'},
{'name': 'lon', 'title': 'Longitude'},
{'title': 'Altitude', 'units': 'm'}
]
在这种情况下,数组中的每个值都代表由数组索引表示的纬度、经度位置的海拔高度(以英尺为单位)。 以下所有操作都返回纬度 = 10、经度 = 5 处的值:
array[10, 5]
array['lon':5, 'lat':10]
array['lat':10][5]
现在假设我们想要将这些数据与另一个维度相同的数组结合起来,\ 该数组表示每个位置的平均降雨量。我们可以轻松地将它们存储为两个\ 独立的数组,或者将它们组合成一个具有以下描述的 3D 数组:
info=[
{'name': 'vals', 'cols': [
{'name': 'altitude', 'units': 'm'},
{'name': 'rainfall', 'units': 'cm/year'}
]},
{'name': 'lat', 'title': 'Latitude'},
{'name': 'lon', 'title': 'Longitude'}
]
现在我们可以使用 array[0] 或 array['altitude'] 访问海拔值,并使用\ array[1] 或 array['rainfall'] 访问降雨量值。以下所有操作\ 都返回 lat=10,lon=5 处的降雨量值:
array[1, 10, 5]
array['lon':5, 'lat':10, 'val': 'rainfall']
array['rainfall', 'lon':5, 'lat':10]
Notice that in the second example, there is no need for an extra (4th) axis description
since the actual values are described (name and units) in the column info for the first axis.
=== 联系 === Luke Campagnola - lcampagn@email.unc.edu
章节作者:未知[15],WarrenWeckesser
附件
{kind=link}